In the past, if you wanted to use data from another website, you often had to resort to ”screen scraping”–or pulling data from a web page by parsing through the raw HTML. In my experience “screenscraping” is a challenge consisting primarily of carefully constructing just the right regex expression to get past a jumble of HTML tags to the content you’re interested in.
Today, the situation seems to have improved somewhat with the widespread use of RSS and new services such as Yahoo Pipes, Dapper.net and OpenKapow.
Out of Date
In the six years since this post was written it seems both Dapper.net and OpenKapow have been acquired. I've updated the links below to point to their current homes on the web but I haven't gone back to verify that they still offer the services described in this article.
Yahoo Pipes is a really cool service that allows you to combine, filter, transform, etc multiple RSS/XML/CSV feeds into a a single RSS or JSON feed. From an end-user standpoint this offers the benefit of creating a custom RSS feeds based on any number of other feeds you may be interested in, e.g. I have to feeds that return job results from SimplyHired and Dice and have merged them together into a single feed and then filtered that feed based on geographic locations that I would consider accepting. One other great point about Yahoo Pipes is that they’ve got a crossdomain.xml file which means you can use them as a proxy for Flex/Flash based apps, see this post for the details.
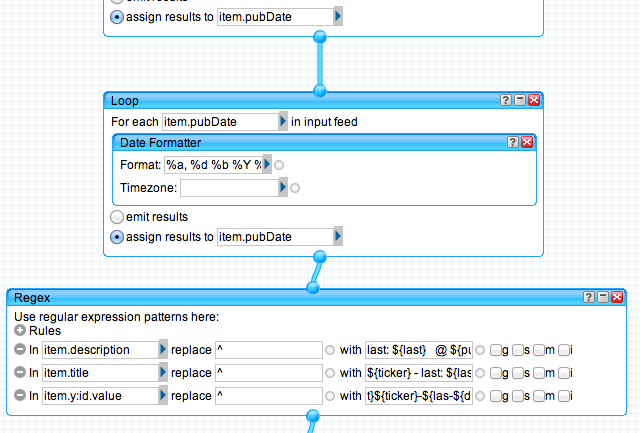
From a developer perspective Yahoo Pipes is cool because it gives you enough control of the RSS feed (i.e. pass in parameters) to essentially treat the resultant RSS and a result set similar to what you’d normally get from a database. The amount of data exposed as RSS, XML or CSV these days really opens up the possibility of combining this data to create interesting applications. Yahoo Pipes helps facilitate the integration of various RSS/XML/CSV sources available on the web to get you just the data you need without the extra trouble of manually pulling it all together yourself.
Now what if there’s no RSS/XML/CSV feed for the data you want to get at? It’s just embedded in HTML… That’s where Dapper.net and OpenKapow come in. They’re both services that help you pull content from a webpage and expose it as an RSS feed (in addition to other formats). Dapper.net is purely web-based and is the “lite” version compared to OpenKapow. OpenKapow requires you to download a fairly large NetBeans based client application to construct your feed. Both tools/services prompt you for the target URL from which you’ll be pulling info and then guide you through the process of identifying exactly what should be pulled from the page. OpenKapow has a zillion options but the downside is you have to learn how to use them all. It also has a limit on the amount of elements that can be returned in your feed. Dapper.net has fewer features but it purely web-based and easier to use, especially for a straightforward task. I’ve used both and feel like I’d prefer something kind of in between … oh well… they’re both useful!